서론
참고한 책
자바 퍼시스턴스 프로그래밍 완벽 가이드 (위키북스)
이 피드에서 기록하는것
자바 퍼시스턴스 프로그래밍 완벽가이드 1장
객체/영속성 이해
패러다임 불일치
Spring JPA / Hibernate
영속성
객체 영속성이란?
- 개별 객체가 프로세스보다 오래 유지될 수 있음을 의미, 각 객체는 저장소에 저장했다가 추후 특정 시점에서 다시 생성할 수 있어야 함.
( 그냥 어플리케이션이 꺼져도 객체의 데이터는 유지되어야 하며, 추후 해당 데이터를 토대로 다시 객체화 할 수 있어야 한다. 라는 뜻)
관계형 데이터베이스 (RDB)
- 데이터를 스키마(기 선언된 제약사항, 데이터유형)에 따라 열(필드, 속성) 과 행(레코드)으로 구조화하여 관리하고,
- 각 테이블의 행과 행을 미리 정의한 관계(키)를 통해 서로 관계(연결)을 가질 수 있게 구성한 시스템
SQL
- Structured Query Langauge : RDB의 데이터를 관리하기 위해 설계된 구조를 가지는 Query 언어
* DDL : 정의언어 (테이블, 제약조건을 정의하는데 쓰임)
* DML : 조작언어 (데이터를 수정, 삭제, 입력 하는데 쓰임)
* DQL : 질의언어 (데이터를 조회하는데 쓰임)
* DCL : 제어언어 (조회권한을 관리하는데 쓰임)
Java에서의 SQL 사용
- Java 앱에서 SQL 데이터베이스를 사용할때는 JDBC API를 통해 DB에 SQL문을 전달
- SQL을 직접 작성하거나, Java 코드를 통해 SQL을 생성하든
쿼리 매개변수를 준비하고, 실행하고, 순회하고, 조회 등 작업 수행 시 JDBC API를 사용해 인수를 바인딩 하는 Low Level 작업이 있을것임
(아마 Java 코드에서 SQL을 만드는것 뿐 아니라, Mybatis 사용도 이 케이스로 간주하는듯 함)
JPA의 사용
- 상기 저수준 작업을 덜어주고, 클래스의 인스턴스를 저장하고 조회하는 방식으로 개발할 수 있음
- 도메인 모델을 사용하는 객체지향 어플리케이션의 맥락에서 데이터 저장 및 공유문제를 고려할 수 있음
- 비즈니스 로직은 java.sql.ResultSet의 Row와 Column을 직접 다루는 대신 각 Table 스키마에 해당하는 클래스의 인스턴스를 로드하고 저장함
- 비즈니스 로직이 Java레벨에서 실행되며, 이때 ResultSet이 아닌 인스턴스를 활용하므로 객체지향 개념을 활용할 수 있음
- 예를들면, GoF 패턴(객체지향 설계에서 자주 반복되는 문제를 해결하기 위해 정리된 23가지 패턴)의 사용이 가능해짐
* Strategy Pattern
- 전략패턴 : 알고리즘을 캡슐화하고, 실행 시점에 교체할 수 있음
- JPA는 영속성 구현체를 교체 가능할 수 있음.
* Mediator Pattern
- 중재자 패턴 : 객체 간 의존관계를 직접 연결하지 않고 중재자를 통해 통신
- SQL 및 JDBC 연결을 개발자가 관리하지 않고 EntityManager가 대신 수행
* Composite Pattern
- 컴포지트 패턴 : 객체를 트리 구조로 구성하여, 개별 객체와 복합 객체를 동일하게 다루는 패턴
- 엔티티간 연관관계를 트리/그래프 구조로 관리 ( User - UserOrders 에서 User를 조회하면 내부적으로 List<UserOrders> 도 다룰 수 있음)
- 다만 모든 상황에서 이렇게 되어야 한다- 는 아님. 어떨때는 ResultSet을 활용하는게 단순하고 빠르고 더 이익이 될 수 있음.
- 실무에서는 JPA 사용 (고수준 작업), SQL 직접 생성(저수준 작업) 두가지 다 적절히 사용하고 있음
UML 클래스 관계유형
책에서 관계유형을 클래스 관계유형으로 표현하고 있어서, 먼저 UML 관계유형을 한번 짚고 넘어간다.
** 일반적으로 UML Class Diagram에서 화살표는 탐색성을 의미한다.
** 화살표가 없다면 "양방향 참조 가능" 이고, 화살표가 있다면 "그 방향대로 단방향 참조" 이다.
* 연관 ( Association )

- 두 클래스가 연관되어있음 / 참조함 을 의미
- 이때, 왼쪽이 오른쪽을 참조함
- 단순히 말하면 A 객체 안에 B 타입의 참조변수가 존재한다는 뜻.
- 다만, A가 B의 생성/소멸을 관리하지는 않음
Java의 개념을 사용하자면 (A의 외부에서 B가 주입됨, B는 A와 독립적으로 생성되고 소멸될 수 있음)
* 일반화/상속 (Generalization/Inheritance)

- 상속 관계를 나타냄
- 이때, 왼쪽 클래스가 오른쪽 클래스를 상속함.
* 실체화/구현 (Realization / Implmenetation)

- 인터페이스를 상속해 클래스에서 실제 기능을 구현함
- 이때 왼쪽이 오른쪽을 구현함
* 의존 (Dependency)

- 왼쪽 클래스가 오른쪽 클래스를 잠깐 사용하거나, 지역변수/메서드 파라미터 등에서 의존하는 관계
- 멤버변수로 A 클래스 내에 B 클래스가 존재하는 association 과는 다르게, 사용만 할뿐 속성으로 들고있지는 않음.
- 예를들면, Association : A의 클래스 내 B 클래스 참조변수 / Dependency : A 클래스 메서드 중 파라미터 B
* 집합 (Aggregation)

- 전체 - 부분 관계 (Has - a)
- 이때, 부분 -----<> 전체
- 즉, 왼쪽이 오른쪽에 속한다.
- 전체와 부분은 독립적으로 존재 가능
- Assocation 은 단순 "참조" 이지만 Aggregation 은 "HAS-A" 개념을 포함하고있다고 함.
- 실무에서도 Aggregation은 잘 안쓰고, Aggregation은 Association의 특수 케이스 취급을 한다고.
* 합성 (Composition)

- 전체 - 부분 관계 (전체가 사라지면 부분도 사라짐)
- 이때, 부분 ---<//> 전체 관계.
- 즉, 왼쪽이 오른쪽에 속한다.
- 전체가 사라지면 부분도 같이 사라짐 (방 -----<///> 집)
패러다임 불일치
객체지향 프로그래밍(OOP) 와 관계형 데이터베이스(RDB)의 사고방식 달라서 발생하는 문제를 통틀어 이야기함.
* 객체지향 패러다임 : 객체, 상속, 다형성, 캡슐화, 그래프 탐색(참조) 기반
* 관계형 데이터베이스 패러다임 : 테이블, 행/열, 외래키기반, Join 탐색
세분성 문제 (Granularity)
객체와 테이블의 표현 단위가 다르다는 데에서 오는 패러다임 불일치
- 객체지향에서는 하나의 개념을 여러개의 작은 Value Object로 나눌 수 있다.
class Member {
private String name;
private Address address;
}
class Address {
private String city;
private String street;
private String zipcode;
}
- 관계형 데이터베이스에서는 보통 Member 테이블 안에 Column을 직접 선언한다.
create TABLE member(
name varchar(40),
city varchar(40),
street varchar(40),
zipcode varchar(20)
)- Address 테이블을 따로 만들 수 있지만 더 나은 성능을 생각할 때, 그리고 Address 자체의 성격을 생각할때 굳이 하나의 테이블을 가질 필요가 없다. - 또한 이렇게 설계하면 사용자와 주소를 함께 조회할 때 Join이 필요하지 않게되어 더 나은 성능이 나온다.
이렇듯, 객체는 "여러개의 값을 한개의 객체로 묶어서 표현" 하는 반면 RDB는 "하나의 객체를 컬럼 여러개로 분리해서 표현" 하기 때문에
표현 방식의 차이에서 오는 매핑하기 번거롭다- 라는 문제를 세분성 문제라고 표현한다.
* UDT 라는 -User-defined Data Type (사용자 정의 데이터 타입)- SQL 의 객체/관계형 확장 기능이 있다고 하나
이종 DB간 이식성도 보장되지 않고 한계가 명백하다고 한다.
JPA에서는 임베디드 타입으로 처리한다.
@Entity
public class Member {
@Id @GeneratedValue
private Long id;
private String name;
@Embedded
private Address address;
}
@Embeddable
public class Address {
private String city;
private String street;
private String zipcode;
}
@Embedded 선언된 필드는 OOP 세계에서 하나의 객체로 처리되고, @Embeddable로 선언된 클래스는 RDB의 세계에서 소유한 필드 전체를 컬럼으로 각각 나눠 선언함으로써 세분성 차이를 해소한다.
** 책에서는 거칠게 세분화된(coarse-grained), 잘게 세분화된(fine-grainded) 단어를 사용했다. 추후에 다시 들여다볼 예정 **
상속 문제
객체지향에서는 다양한 상속구조를 정의할 수 있다.
class Item {
String name;
int price;
}
class Book extends Item {
String author;
}
class Movie extends Item {
String director;
}
그러나, DB에서는 상속개념이 없다. 단순히 행/열 구조일 뿐.
여기서 더 나아가, 모델에 상속을 도입하면 "다형성"을 고려하기 시작해야한다.
예를들어, User가 Item을 구매했다고 하자.
그렇다면 런타임에서 User는 Item 하위 클래스 중 하나인 Movie를 참조할 수 있다. 이때, 쿼리가 Item의 하위클래스인 Movie 인스턴스를 반환하는
다형적 쿼리를 작성해야 할 수도 있다.
위와같이 SQL에서는 이런 Java의 상속관계와 다형적 연관관계를 표현할 수 있는 표준화된 방법이 없다.
이에서 오는 문제를 "상속 문제" 라고 표현한다.
JPA에서는 상속문제를 3가지 매핑전략을 제공함으로서 해결한다.
@Inheritance(strategy = {}) 로 전략을 지정할 수 있다.
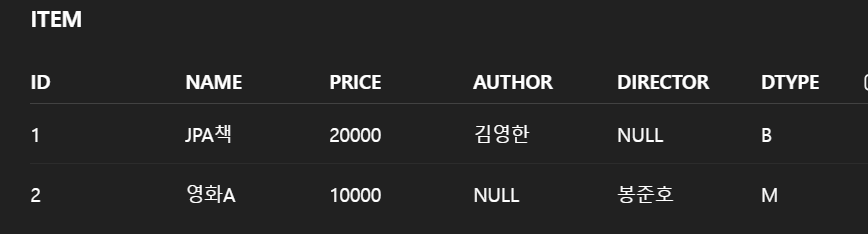
단일테이블전략(SINGLE_TABLE)
- 모든 자식 엔티티를 하나의 테이블에 저장
- DTYPE 컬럼으로 구분
- 쿼리는 단순해지고 JOIN이 필요없어지나, 불필요한 NULL 컬럼이 많아질 수 있음
@Entity
@Inheritance(strategy = InheritanceType.SINGLE_TABLE)
@DiscriminatorColumn(name = "DTYPE") // 자식 타입 구분용 컬럼
public abstract class Item {
@Id @GeneratedValue
private Long id;
private String name;
private int price;
}
@Entity
@DiscriminatorValue("B")
public class Book extends Item {
private String author;
}
@Entity
@DiscriminatorValue("M")
public class Movie extends Item {
private String director;
}
조인 전략 (JOINED)
- 부모와 자식을 테이블을 나눠서 저장, 조회시 조인 사용
- 정규화가 잘 지켜지고, 중복이 없어지나 조회시 항상 JOIN이 발생하게 된다.

구현클래스마다 테이블만들기 전략(TABLE_PER_CLASS)
- 자식 클래스마다 테이블을 따로 생성
- 부모 테이블 없음, 조회시 UNION 필요
- 잘 안쓴다.

또한, 이 방법으로 해결하면 다형적 쿼리도 만족할 수 있다.
기본 다형쿼리 (부모타입으로 조회 시)
- SINGLE_TABLE: 한 테이블에서 DTYPE으로 구분 → 단순 SELECT
- JOINED: 부모+자식 조인 발생
- TABLE_PER_CLASS: 자식 테이블들을 UNION
위의 동작 방식 하에
List<Item> items = em.createQuery("select i from Item i", Item.class)
.getResultList();
위와 같은 코드로 조회할 수 있다. 이때, items에는 부모인스턴스와 자식인스턴스가 혼재해있게된다.
혹은, 지네릭을 사용하거나, 동적 프로젝션을 사용할수도 있다.
// 지네릭
public <T extends Item> List<T> findByType(Class<T> type) {
TypedQuery<T> q = em.createQuery(
"select i from Item i where type(i) = :type", type);
q.setParameter("type", type);
return q.getResultList();
}
List<Book> books = findByType(Book.class);
List<Movie> movies = findByType(Movie.class);
// 동적 프로젝션
// 리파지토리계층 선언
public interface MemberRepository extends JpaRepository<Member, Long> {
// <T> 제네릭으로 선언
<T> List<T> findByUsername(String username, Class<T> type);
}
// 호출 -> 엔티티 프로젝션
List<Member> members = memberRepository.findByUsername("junhoon", Member.class);
이 프로젝션 기능은 2년전에 잠깐 공부한 적이 있는데, 이후 책을 돌파하면서 다시한번더 살펴보겠다.
객체동일성 문제
Java에는 "동일성"에 대해 두가지 개념이 있다.
- 인스턴스 동일성 : 인스턴스의 메모리 번지 수 값이 같은지를 판단 ( a == b )
- 인스턴스 동등성 : 인스턴스의 값을 비교, equals() 메서드 구현으로 결정됨 (값에 의한 동등성)
그러나, DB에서 "동일성 비교는" PK(Primary Key) 값의 비교로 표현된다.
이때, equals() 나 == 는 항상 기본키 값 비교와 상응하지 않는다.
결국 객체 동일성 문제는 "DB의 행을 어떤 키로 식별할 것인가" 와 직결되는 문제이다.
이때, 현실세계에서 이미 식별자로 사용되는 값인 "자연키" 와
테이블 행을 구분하기 위해 만든 비즈니스 레이어에서 별 의미를 가지지 않는 "대리키" (JPA에서 @GeneratedValue로 씀)
를 선택하는 전략적 움직임도 필요하다.
JPA에서 객체동일성 문제를 해결하기 위해 영속성 컨텍스트(1차캐시)를 이용한다고.
동일한 Key로 조회하면 DB를 거치지 않고 캐시에서 꺼내서 같은 인스턴스를 반환하는 전략을 사용한다고 한다.
그렇게되면, 주소값이 같아서 동일성 비교가 정상적으로 수행되게 되는것.
연관관계 문제
OOP 세계에서는 '객체 참조'를 이용해 관계를 나타내지만, RDB세계에서는 외래키 제약조건이 연관관계를 나타내는 값임.
이 두 관계표현방식은 차이점이 크다.
OOP 세계의 객체참조에는 방향성이 있다 (A의 참조형 멤버변수 B는 A->B 단방향이다).
만약 B에서도 A를 참조할 수 있어야 한다면 연관관계를 맺는 클래스에서 각각 한번씩 총 2번 선언해야 한다.
그러나 RDB 세계에서는 JOIN 연산자를 활용해 연관관계를 만들 수 있어서 특정방향으로의 탐색의 의미가 없다.
문제는, 이러한 "방향성 없이 JOIN을 통해 상호조회가 가능한 개방된 Database 형 모델을,
OOP의 방향성이 있는 객체 참조 탐색 방식에 매핑"하는 데에서 발생한다.
예를들어 Java의 다대다(many-to-many) 환경을 보면,
public Class User {
private Set<BillingDetails> bills = new HashSet<>();
}
public Class BillingDetails {
private Set<User> users = new HashSet<>();
}위와같은 비즈니스 모델이 구현될 수 있다.
이경우, RDB에서 다대다 연관관계를 표현하려면 별도의 "관계 테이블"이 요구된다.
create table rel_user_bill(
rel_id integer auto_increment primary key,
user_id integer,
bill_id integer,
FOREIGN key (user_id) references user(user_id),
FOREIGN KEY (bill_id) references bill(bill_id)
)
insert into rel_user_bill(DEFAULT, 1,1);
insert into rel_user_bill(DEFAULT, 1,2);
insert into rel_user_bill(DEFAULT, 2,3);
insert into rel_user_bill(DEFAULT, 2,4);그런데, 이런 관계 테이블은 도메인 모델의 어디에도 표현이 되지 않는다. 이런 부분에서 오는 문제를 "연관관계 문제" 라고 표현한다.
이와 같은 방향성 문제와 더불어 "연관관계의 주인"을 결정해야 하는 문제와 객체 탐색 문제가 있다.
연관관계의 주인이란, 객체 양방향 매핑 시 외래키를 관리할 엔티티가 정해져야 한다는 뜻.
또한 객체 탐색 문제는, 객체는 user.getBill().getName()) 이렇게 참조를 따라가는데, DB는 FK로 조인을 해야 한다는 점.
따라서 조회를 하는 방식이 달라져야 한다는 문제가 있다. 즉시 로딩(EagerLoading) 이면 JOIN절로 조회해야 하고,
지연 로딩(Lazy Loading)이면 프록시 객체를 사용하는 시점에 Select절을 날려야 한다는 점.
JPA에서는 아래와 같은 방법으로 처리한다.
1. 방향성 문제 -> @ManyToOne 혹은 @OneToMany(mappedBy = ...) 으로 방향성을 명시한다.
2. 연관관계 주인 문제 -> FK가 선언될 테이블에 @JoinColumn(name = "...")을 명시해서 그 테이블에 FK를 선언
3. 객체 탐색 문제 -> LazyLoading 혹은 EagerLoading을 지원
@Entity
public class Member {
@Id @GeneratedValue
private Long id;
private String name;
@ManyToOne
@JoinColumn(name = "team_id") // FK
private Team team;
}
@Entity
public class Team {
@Id @GeneratedValue
private Long id;
private String name;
@OneToMany(mappedBy = "team")
private List<Member> members = new ArrayList<>();
}데이터 탐색 문제
OOP(Java)에서 데이터에 접근하는 방법과 RDB에서 객체와 관계에 접근하는 방식은 크게 다르다.
주로 Java에서는 user.getBillingDetails().iterator().next() 과 같이 한 인스턴스에서 다른 인스턴스로 초점을 이동하는 반면
RDB에서 Select -> 결과를 가지고 다시 Select -> 그 결과를 가지고 다시 Select 하는것은 비효율적이다.
RDB에서 효율을 챙기려면 "DB에 대한 요청 횟수를 줄이고, SQL 쿼리수를 최소화" 하는것이 옳다.
따라서 RDB에서는 주로 관심사를 줄여나가 쿼리를 단순화 하거나, 관심사를 넓혀 JOIN을 통해 한번에 조회한다.
즉, 효율적으로 쿼리를 사용하려면 객체망 탐색 전 "어느 부분까지 접근할 지" 결정을 한 상태여야 하며, 결정을 잘못한다면 너무 많은 데이터를 조회함에 따라 메모리 낭비가 발생하거나, 극히 큰 카테시안 곱 발생으로 인해 SQL 자체에 과부하를 줄 수도 있다.
이를 해결하기 위해 지연 로딩(Lazy Loading,연관관계 있는 인스턴스에 `접근`할 때 데이터를 가져오도록) 이 사용되는데, 여기서 큰 문제가 발생한다.
이 지연 로딩은 SQL 입장에서는 비효율적이다. SQL이 여러번 발생하기 때문. 여기서 발생하는게 n+1 문제이다.
public Class User {
private Set<BillingDetails> bills = new HashSet<>();
}
public Class BillingDetails {
private Set<User> users = new HashSet<>();
}이 코드에서, 임의의 User의 여러개의 BillingDetails에 접근하려면,
User 조회 1번, 각 BillingDetails의 PK로 SELECT WHERE가 N번 발생하기 때문. 이렇게 되면 SQL 입장에서는 몹시 비효율적인 상황이 온다.
이런 n+1 문제와 큰 카테시안 곱은 JPA를 사용하는 동안에는 꾸준히 해결해야 하는 문제이며
이 책에서는 이후에 하이버네이트로 효율적으로 데이터를 가져오는 법을 설명하겠다고 한다.
먼저 GPT에게 물어본 결과 아래와 같은 전략을 제시한다.
1. Fetch JOIN : 한번에 연관 엔티티까지 다들고오기 (컬렉션 fetch + 페이징은 JPA 표준상 불능, 메모리 페이징 폭증이 단점)
2. EntityGraph (메서드 단에서 필요한 연관만 선언적으로 한번에 로딩 (1번과 동일한 제약)
3. BatchFecth (지연 로딩시 여러 FK를 모아 IN 쿼리로 한번에 당겨오기(Hibernate 기능)
ORM, JPA, Hibernate, SpringData
ORM(Object Relation Mapping)?
애플리케이션 클래스와 SQL Database의 스키마 간 매핑을 설명하는 메타데이터를 사용,
Java 애플리케이션의 객체를 RDBMS의 테이블에 자동으로 영속화 하는 기술
JPA (Jakarta Persistence API)
객체 및 객체/관계형 매핑의 영속성을 관리하는 API 정의 명세
영속화 하기 위한 일들을 명시
정의 주요 예시
- 영속성 클래스 및 프로퍼티가 DB의 스키마와 어떻게 관련이 있는지 지정하는 매핑 메타데이터를 정의
- JPA는 @에 의존함 (다만 XML 작성도 가능)
- 영속성 클래스의 인스터스를 대상으로 CRUD 작업을 수행하기 위한 API를 정의
가장 대표적인 API로 데이터 저장과 로딩을 담당하는 javax.persistence.EntityManager가 있음
- 클래스 및 프로퍼티를 참조하는 쿼리를 지정하기 위한 언어와 API를 정의
이 언어를 Jakarta Persistence Query Langauge라 하며, SQL가 비슷한 형태를 취함.
- 영속성 엔진이 트랜잭션 방식으로 동작하는 인스턴스와 상호작용해 변겅 감지, 연관관계 Fetch, 기타 최적화 수행 방법을 정의
- 기본적인 캐싱 전략을 정의
Hibernate
가장 널리 사용되는 JPA의 구현체
영속화를 어떻게 수행할지 결정
Hibernate의 장점
- 생산성 : Hibernate가 반복적인 작업을 상당수 제거함에 따라 개발자로 하여금 비즈니스 문제에 집중할 수 있게함.
- 유지보수 용이성 : Hibernate가 만든 자동화된 ORM은 코드 줄 수를 줄여서 시스템을 더 이해하기 쉽게만듬
- 성능 : 손수 작성한 영속성 코드보단 느릴지라도(Java가 어셈블리어보다 느리듯) 최적화 할 여지는 언제나 많음
- 공급자 독립성 : 이종간 DB 호환성 (DB별 방언 등..)을 걱정할 필요 없음
Spring Data
영속성 계층 구현을 더욱 효율적으로 만들어준다.
~ Commons
모든 스프링 데이터 모듈을 지원하는 핵심 개념을 제공
~ JPA
JPA 구현(Hibernate) 위에 추가 레이어를 제공
메서드 명을 토대로 SQL 쿼리를 작성하는 등 자체적 기능을 제공
Spring Data(Spring Data JPA)를 사용함으로써 얻는 이점
- 공유 인프라 : ~Commons 프로젝트에서 자바 클래스를 영속화 하기 위한 메타데이터와 기술 중립적인 리파지토리 인터페이스를 제공
- DAO 구현 제거 : JPA 구현은 자체적으로 DAO 패턴을 사용. 데이터베이스의 세부 사항을 숨기면서 애플리케이션 호출을 영속성 계층에 매핑
사실 이 부분은 잘 와닿지 않는다.
- 자동 클래스 생성 : Spring Data JPA를 사용할경우 DAO 인터페이스의 일종이자 JPA 전용인 JpaRepository를 자동으로 생성함
- 메서드 기본구현 : Spring Data JPA는 Repository 인터페이스에 정의된 메서드에 대한 기본구현(CRUD)을 자동으로 생성.
- 생성된 쿼리 : 명명패턴에 따라 Repository 인터페이스에서 메서드를 정의할 수 있음. 자동으로 이름을 파싱해서 쿼리를 생성.
- 필요한 경우 DB 접근 : Spring Data JDBC를 통해 DB와 직접 통신도 가능함!
* 대규모 분산 관계형 시스템
- 분산 데이터베이스는 여러 노드(DB 인스턴스를 구동하는 물리적인 개념의 서버)에 분산시켜서 저장함
- CAP 정리에 따르면 분산시스템은 Consistency(일관성), Availability(가용성), Partition tolerance(파티션 장애내성)을 동시에 갖출 수 없음.
* 일관성
- 분산 DB 상 어떠한 노드와 통신했던간에 동일한 데이터를 조회할 수 있어야 함.
다르게 말하면, A노드에 INS = 1이 "쓰기" 작업 되었다면, 모든 복제본에 반영이 되어서 Z노드에서도 INS = 1이 조회되어야 함.
그러나, 시스템이 모든 인스턴스에 변경 내역을 즉각 반영하는것은 사실상 불가능에 가까움.
따라서 일관성의 목표는 데이터 동기화가 "충분히" 빨라, 사용상 문제 없게 하는것임
* 가용성
- 모든 요청이 응답받을 수 있어야함. 작업이 성공했든 실패했든 일단 응답을 받을 수 있어야 한다.
즉, 시스템이 중단되는 일 없이 언제든 사용가능해야한다.
* 파티션 장애내성
- 노드간 통신이 끊어진 상황에서도 시스템은 여전히 작동해야 함.
즉, A 노드가 뻗더라도 C 노드가 응답에 성공해서 요청받은 Request에 적절히 응답을 하는 등, 시스템은 정상작동을 할 수 있어야함.
* CAP 이론?
- 분산 데이터베이스 시스템은 분할발생시(파티션 장애발생시) 일관성과 가용성 중 하나를 희생해야함을 의미.
- 빗대어 말하자면, DB 노드 A,B 2개중 A노드가 뻗었을 때, 쭉 서비스할지(B노드에서 서비스, A노드는 변경된 내용을 모름, 일관성 희생)
서비스를 중단시키고 A노드 재기동을 실행할지(A노드가 향후 변경점을 따라올 수 있게 서비스를 중단, 가용성 희생)
상기 결정을 통해 둘중 하나는 희생될 수 밖에 없다는 이론
'공부일기 : JPA' 카테고리의 다른 글
| JPA 1권 독파하기(6) : 영속성 클래스 매핑 (0) | 2025.10.05 |
|---|---|
| JPA 1권 독파하기(5) : 1부 / 엔티티 기초 영역 갈무리 (0) | 2025.10.04 |
| JPA 1권 독파하기(4) : Spring Data JPA 다루기 / 엔티티 (0) | 2025.10.04 |
| JPA 1권 독파하기(3) : 도메인 모델과 메타데이터 (0) | 2025.09.21 |
| JPA 1권 독파하기(2) : 하이버네이트, 스프링 데이터 프로젝트 (1) | 2025.09.10 |